La folle montée en puissance du NLP
A l’instar du traitement de l’image, le traitement automatique du langage naturel, ou Natural Language Processing (NLP), a fait un grand pas en avant avec l’avènement de l’Intelligence Artificielle (IA).
A partir des années 2000, la quantité de corpus textuels sur la toile et la puissance des machines ont permis d’améliorer significativement l’approche statistique du traitement du texte. Dès 2014, les benchmarks, comme WMT sur la traduction automatique, ont ensuite appuyé l’intérêt d’une approche par machine learning avec les réseaux de neurones récurrents et l’apprentissage automatique de la représentation du texte (embedding).
Dès lors, le NLP n’est plus exclusivement l’affaire des spécialistes du langage. Au sein des entreprises, les scientifiques de la donnée ont pu s’approprier l’usage des techniques neuronales de NLP (embeddings, RNN, LSTM) pour exploiter les données textuelles. Seul « hic », l’accès à ces méthodes demande une importante volumétrie de données, le plus souvent « annotées », impliquant souvent un temps d’apprentissage conséquent.
Bien évidemment, les performances exceptionnelles atteintes avec l’apprentissage profond (deep learning) sur les tâches, notamment de classification, de traduction et de génération de texte, restent encore perfectibles. L’apprentissage par récurrence – comprendre « par itération » – est lent et peu adapté aux textes longs. Malgré ces limites, un cap a été franchi ! Et l’espoir de faire avancer davantage le domaine est bien palpable.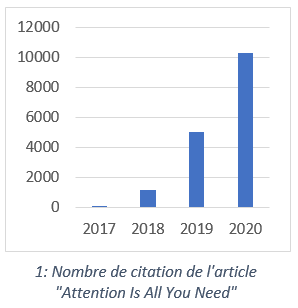
Le monde du NLP est toujours en pleine effervescence lorsque Google Brain publie en juin 2017 l’article scientifique « Attention Is All You Need ». Il provoque l’effet d’une bombe dans la communauté. Le mécanisme « attention » combiné à une architecture particulière dites « transformers » y est décrit. Cette architecture établit une nouvelle référence dans la tâche de traduction automatique (score WMT2014 de 41,8). La force des « transformers » réside dans leur capacité à apprendre automatiquement les dépendances entre plusieurs séquences d’un texte et à les retenir pendant la phase d’apprentissage. L’astuce de l’« attention » réduit drastiquement le coût machine et permet la parallélisation des calculs. Si bien que les 213 millions de paramètres à estimer de l’architecture ne sont plus un problème pour la recherche : quelques jours suffisent…
A compter de ce papier, l’architecture « transformers » fascine et établit plusieurs records dans différentes tâches du NLP. Très vite, des variantes de l’architecture proposée par Google naissent pour améliorer certains concepts, mais pas seulement.
En 2018, un nouveau paradigme « pre-training and fine-tuning » prend forme avec OpenAI (GPT) et Google (BERT). Ces deux géants de l’IA démontrent l’intérêt du pré-entrainement des « transformers » sur des données textuelles non labellisées. Une fois pré-entrainé sur des tâches génériques, le modèle est capable de se spécialiser sur une tâche à l’aide d’un jeu de données adapté : le fine-tuning. Au-delà des termes précis, l’idée est de mettre à disposition un outil quasi prêt à l’emploi dans divers domaines : question-réponse, classification de documents, génération de texte, traduction, labélisation de séquence…
Naturellement, rien n’est magique. La phase de pré-entrainement est une étape d’apprentissage de représentation d’une langue, du contexte et de la sémantique. Elle nécessite des gigas octets de données textuelles, une infrastructure GPU, ce qui représente un coût important. C’est un investissement démesuré pour la grande majorité des entreprises. Quant à la seconde étape de fine-tuning, elle est abordable à condition de détenir un jeu de données suffisant pour spécialiser le modèle.
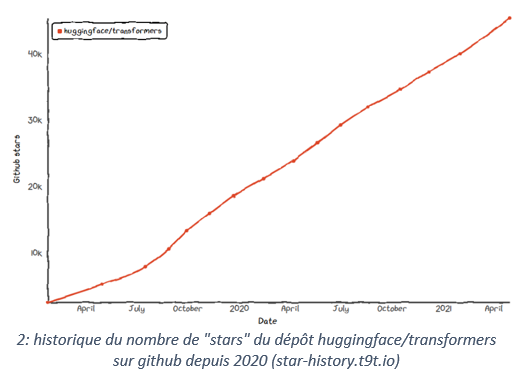 La recherche en NLP est en plein essor et la technique est au rendez-vous pour permettre la mise en œuvre des méthodes. Reste un dernier acteur important pour donner l’opportunité aux entreprises de saisir ces innovations : la communauté des développeurs. Nul n’est sans connaître la plateforme de collaboration de développement Github qui donne l’opportunité à tous de partager son code et ses idées. Paperswithcode est une source très riche pour faire le lien entre théorie et pratique. Mais la société HuggingFace, fondée par deux Français (Clément Delangue & Julien Chaumond, cocorico !), s’impose aujourd’hui comme la ressource référence, en python, pour le traitement du langage naturel basée sur les modèles « transformers ». Leur technologie, open source, se distingue par sa prise en main rapide et la mise à disposition des nouveautés issues du domaine de la recherche. Depuis peu, l’entreprise propose une plateforme de partage de modèles déjà « fine-tunés », facilitant leur usage.
La recherche en NLP est en plein essor et la technique est au rendez-vous pour permettre la mise en œuvre des méthodes. Reste un dernier acteur important pour donner l’opportunité aux entreprises de saisir ces innovations : la communauté des développeurs. Nul n’est sans connaître la plateforme de collaboration de développement Github qui donne l’opportunité à tous de partager son code et ses idées. Paperswithcode est une source très riche pour faire le lien entre théorie et pratique. Mais la société HuggingFace, fondée par deux Français (Clément Delangue & Julien Chaumond, cocorico !), s’impose aujourd’hui comme la ressource référence, en python, pour le traitement du langage naturel basée sur les modèles « transformers ». Leur technologie, open source, se distingue par sa prise en main rapide et la mise à disposition des nouveautés issues du domaine de la recherche. Depuis peu, l’entreprise propose une plateforme de partage de modèles déjà « fine-tunés », facilitant leur usage.
En 2020, le NLP n’est définitivement plus une affaire de spécialiste du langage, ni même de spécialiste de la donnée. Les technologies comme HuggingFace ont ajouté plusieurs couches d’abstraction permettant à des développeurs, des ingénieurs de la donnée ou en Machine Learning de mettre en place une valorisation du NLP au sein des entreprises.
Le NLP, domaine d’investigation du Lab Innovation
Depuis près de 3 ans, Le Lab Innovation consacre une grande partie de ses recherches autour des problématiques textuelles. Après la construction d’un Chatbot RH et la création d’un moteur de recherche interne (cf. billet publié en 2019), nous avons à cœur de contribuer à la démocratisation du traitement de la langue française au sein des entreprises.
Génération de texte (NLG)
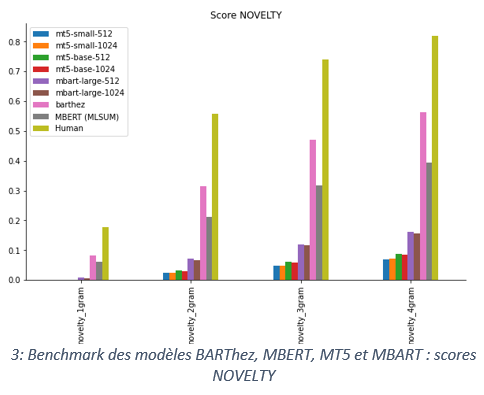 Nous nous sommes pris au jeu de vouloir générer automatiquement un résumé à partir d’un contenu. Imaginez un compte rendu de réunion s’écrire automatiquement, capturant l’essentiel de l’information ? Quel gain de temps ! Avant d’atteindre un objectif aussi ambitieux, il est nécessaire d’évaluer la qualité des résumés sur des bases de données plus simples. Nous avons donc essayé de résumer l’information d’un article de presse français grâce à un modèle multilingue pré-entrainé (mBART). Les données sont issues du corpus MLSUM (The Multilingual Summarization), une base de presse multilingues publiée par reciTAL et le CNRS. Nos résultats ne rivalisent ceux du modèle BARThez (premier modèle BART pré-entrainé sur un grand corpus français monolingue), sorti peu de temps après nos travaux. Les résultats montrent néanmoins la limitation des modèles multilingues et du fine-tuning sur cette tâche. Notre modèle est disponible sur la plateforme HuggingFace : lincoln/mbart-mlsum-automatic-summarization et nous consacrerons prochainement un billet sur ces travaux.
Nous nous sommes pris au jeu de vouloir générer automatiquement un résumé à partir d’un contenu. Imaginez un compte rendu de réunion s’écrire automatiquement, capturant l’essentiel de l’information ? Quel gain de temps ! Avant d’atteindre un objectif aussi ambitieux, il est nécessaire d’évaluer la qualité des résumés sur des bases de données plus simples. Nous avons donc essayé de résumer l’information d’un article de presse français grâce à un modèle multilingue pré-entrainé (mBART). Les données sont issues du corpus MLSUM (The Multilingual Summarization), une base de presse multilingues publiée par reciTAL et le CNRS. Nos résultats ne rivalisent ceux du modèle BARThez (premier modèle BART pré-entrainé sur un grand corpus français monolingue), sorti peu de temps après nos travaux. Les résultats montrent néanmoins la limitation des modèles multilingues et du fine-tuning sur cette tâche. Notre modèle est disponible sur la plateforme HuggingFace : lincoln/mbart-mlsum-automatic-summarization et nous consacrerons prochainement un billet sur ces travaux.
Classification de document
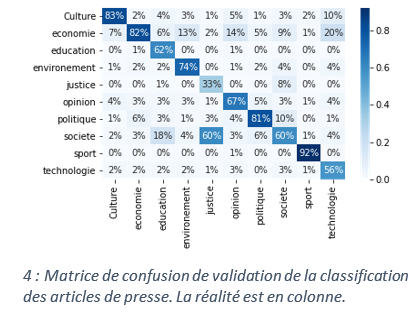
Les auteurs de MLSUM proposent également d’utiliser leur base pour entrainer un modèle qui détecte les topics des articles. Pour démontrer l’intérêt des « transformers » sur de telles tâches, nous avons construit une classification des articles français en dix topics différents. Ces travaux ont été réalisé à l’aide d’une étape de fine-tuning du modèle FlauBERT. Notre modèle est aussi disponible sur la plateforme HuggingFace : lincoln/flaubert-mlsum-topic-classification. Notons qu’il aura fallu peu d’exemples dans chaque topic pour entrainer un modèle ayant des performances raisonnables.
Question-Réponse
La tâche de «Question–Answering » est prometteuse et les données en langue française existent ! De plus, quelques modèles sont déjà disponibles en Français. L’usage de ces modèles permettraient de générer automatique des « FAQ » et de questionner automatiquement des bases de connaissances. Au Lab, nous avons lancé un projet pour affiner l’apprentissage de ces modèles en générant automatiquement des questions. A suivre !
Encore du chemin à parcourir…
En quelques années, le traitement automatique du langage naturel (TALN) est devenu accessible, en quelques lignes de codes. Cependant, notre usage intensif de HuggingFace, nous amène à penser que toutes les barrières ne sont pas encore levées.
Tout d’abord, les couches d’abstraction peuvent ralentir le développement en dehors de l’usage principal. Et nous pensons qu’une compréhension profonde des architectures des modèles ne doit pas être négligée. Les spécialistes de la donnée ont encore leur place dans ce paradigme.
Ensuite, ces technologies sont gourmandes en ressource machine. L’entrainement et le déploiement des modèles « transformers » peuvent relever quelques challenges d’infrastructure au sein d’une entreprise. Le cloud peut être une solution mais il n’échappe pas à certaines limites. Là encore, les ingénieurs et les architectes de la donnée ont de beaux jours devant eux.
Enfin, seuls quelques modèles pré-entrainés « transformers » en français sont disponibles à ce jour, ce qui est peu comparé à des dizaines de modèles en langue anglaise. Mécaniquement, cette différence se ressent dans les usages possibles du NLP dans la langue française. Mais rien n’est perdu pour autant : de nouveaux modèles et jeux de données français commencent à émerger.
La révolution NLP semble se poursuivre en 2021. D’un point de vue technique, les plateformes transforment le NLP en un service via l’usage d’API (on parle de « NLP as a service »), notamment avec l’AutoNLP de HuggingFace. Par ailleurs, les géants de l’IA transforment leurs rêves les plus fous grâce à leurs ressources illimitées : le modèle GPT-3 (OpenAI), considéré comme l’une des plus importantes avancées réalisées dans le domaine de l’IA, pèse 175Go pour 175 milliards (!) de paramètres. La recherche explore des nouvelles couches d’abstraction en unifiant toutes les tâches de NLP en une (T5 de Google par ex.).
« On n’arrête pas le progrès » dit-on. Quand bien même cela serait possible, la créativité reste notre maître mot pour répondre aux enjeux du traitement des données textuelles en entreprise.
Le Lab Lincoln.