Data Mesh est sans conteste le buzzword de ce début d’année. Si vous n’avez jamais entendu parler de Data Mesh, une simple recherche “trends in data 2022” suffira à vous convaincre que vous avez peut-être raté quelque-chose. Introduit par Zhamak Dehghani en 2019, le terme décrit une architecture de données distribuée et orientée-métier. Le Data Mesh émerge dans un contexte où il devient manifeste que les lacs de données, architecture monolithique et centralisée héritée de l’ère du Big Data, ont échoué à tenir toutes leurs promesses.
Il est vrai que le virage du Big Data, opéré au tournant des années 2010, ne fut pas — d’un point de vue architectural du moins — le changement de paradigme souvent décrit. Certes, l’entrepôt de données cédait sa place au lac de données, dont la permissivité en matière de structure de données augmenta considérablement les capacités d’ingestion des plateformes modernes. Toutefois, l’architecture de ces plateformes restait sensiblement la même : in fine, un monolithe ne faisait qu’en remplacer un autre. En effet, à l’instar d’un entrepôt, l’architecture des lacs de données reposent sur un unique pipeline, généralement décomposé en étapes de traitement fortement couplées et dont la gestion est confiée à une équipe SI centralisée.
Avec le recul, il s’avère aujourd’hui que le passage à l’échelle attribué à l’adoption des lacs de données fut pour le moins en trompe-l’œil. D’abord, la nature monolithique des lacs de données a progressivement dégradé le time-to-data. À mesure que les sources de données et les cas d’usage se multiplient, respectivement en amont et en aval du lac, le pipeline tend à s’engorger et l’équipe SI voit impuissante son backlog s’épaissir. De même, le caractère centralisé de la gestion des lacs de données a eu des effets délétères sur la qualité des données. Bien que propriétaire du lac de données, l’équipe SI n’est aucunement responsable de son contenu. Une poignée d’ingénieurs — aux connaissances métier réduite qui plus est — ne pouvant assurer, à eux seuls, la qualité des téraoctets de données.
La faible scalabilité des architectures monolithiques est un problème bien connu des ingénieurs logiciel, lesquels privilégient désormais des systèmes distribués, généralement découpés en composants indépendants — appelés microservices. Dans la plupart des cas, ces microservices sont gérés par des équipes autonomes capable de déployer de nouvelles fonctionnalités sans risquer de compromettre le reste du système. En un sens, Le Data Mesh est essentiellement une transposition de cette approche — dite par microservices — à l’architecture de données.
Dans la pratique, le Data Mesh suppose de décentraliser la propriété des données de l’équipe SI vers les domaines fonctionnels. Afin d’éliminer le goulot d’étranglement que représente un pipeline unique, ces domaines seraient de fait en charge de construire et maintenir leur propre pipeline de données, et cela de manière indépendante. Pour ce faire, des équipes pluridisciplinaires constituées au sein de chaque domaine disposeraient, sur étagère, de tous les outils nécessaires à la création, au déploiement puis au run des datasets. Enfin, à l’image d’un produit de consommation, ces datasets devront satisfaire des besoins utilisateur clairement identifiés avant de pouvoir être développés puis distribués par les équipes domaine concernées.
Prises individuellement, ces idées n’ont pourtant rien de nouveau. D’ailleurs, Dehghani ne se cache pas de les avoir piochées çà et là afin de construire selon ses propres mots une “architecture à l’intersection de trois techniques” largement plébiscitées dans l’industrie de la tech (voir Fig. 1).
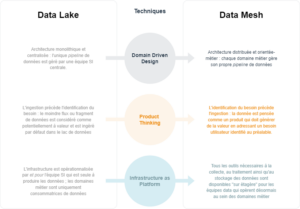
En architecture de données — comme en toutes choses par ailleurs — la recherche de la martingale est vaine. Si les architectures monolithiques présentent des limites certaines, “casser le monolithe” posera, à coup sûr, d’innombrables défis aux Chief Data Officers. Parmi ceux-ci, nous en anticipons deux.
Le premier de ces défis sera de mitiger le risque accru de silotage des données que représenterait une décentralisation excessive de l’architecture de données. Au-delà des caricatures qui dépeignent le Data Mesh en Shadow IT institutionnalisé, de sérieux doutes peuvent être formulés quant au degré d’interopérabilité de données produites de manières indépendantes par des équipes domaines autonomes, comme le préconise Dehghani. De toute évidence, redéfinir les règles de gouvernance des données afin de les adapter à une architecture distribuée semble être un préalable avant toute migration vers un Data Mesh.
Le second défi sera vraisemblablement posé par les directions métiers qui sont par nature réticents à partager leurs données avec le reste de l’entreprise, faisant montre à cet égard d’un certain « tribalisme ». Dans ces conditions, leur octroyer le monopole de la production des données pourrait nuire à la disponibilité de certaines données stratégiques au sein de l’entreprise. La mise en place, dans le cadre d’un Data Mesh, de mécanismes d’incitation susceptibles d’aligner l’intérêt des directions métier avec celui de l’entreprise serait à ce titre une possibilité à étudier sérieusement.
Des entreprises de e-commerce se sont déjà lancées et ont déjà adopté des architectures de données inspirées du Data Mesh. D’autres, ayant opté ces dernières années pour la mise en place de Data Factory organisées en features teams Métiers, réfléchissent aujourd’hui à une adaptation de leur modèle. Cette stratégie Data mérite d’être pensée en amont de tout changement opérationnel et organisationnel pour en mesurer les impacts et les améliorations recherchées notamment en terme de TTM. Lincoln accompagne ses clients dans ces réflexions et dans l’implémentation de ces infrastructures. Nous vous tiendrons au courant des success stories autour du concept éprouvé de Data Mesh !-)