Data Warehouse et Datamart
Dans les années 90, les entreprises ont mis en place leur Système d’Information Décisionnel pour centraliser et historiser leurs données opérationnelles.
D’un point de vue « stockage », on trouve alors des entrepôts de données ou Data Warehouse destinés à recueillir toutes ces données, essentiellement structurées, entrant dans le Système d’Information Décisionnel de l’entreprise par l’intermédiaire de jobs ETL développés, maintenus et exploités par l’IT.
La transformation selon des règles fonctionnelles et la mise à disposition de ces données conduit à la création de Datamarts orientés métiers et en général relativement silotés.
D’un point de vue technique, les Data Warehouse comme les Datamarts sont hébergés dans des bases de données relationnelles et se caractérisent par leur capacité à fournir de la donnée consistante, standardisée et adaptée aux besoins de la Business Intelligence.
Data Lake
Au milieu des années 2000, le « data déluge » et le besoin de traiter des données semi-structurées ou non structurées (images, vidéos, sons), d’ingérer des données en temps réel et de gérer des volumétries plus conséquentes (notamment générées par l’IOT) conduit à la création dans les entreprises d’un Data Lake le plus souvent basé sur Hadoop et plus précisément sur une des distributions phares implémentant cette technologie (Cloudera, Hortonworks, MapR).
Dans le Data Lake, les données sont chargées directement depuis les sources et stockées dans un format brut et c’est ensuite seulement que les transformations sont appliquées. On passe d’un process de type ETL (Extract, Transform, Load ) à un process de type ELT (Extract, Load, Transform).
Le Data Lake se caractérise alors par sa capacité à héberger tout type de données et en particulier les Big Data à un coût relativement réduit car mettant en œuvre des clusters basés sur des machines bon marché.
Cependant, le stockage de données brutes dans un Data Lake rend leur accès parfois complexe avec les outils analytiques ou BI. L’absence de support des propriétés ACID (atomicité, cohérence, isolation et durabilité) peut conduire à des performances médiocres lors des opérations de requêtages et de jointures.
Mais la problématique principale qui est posée par une architecture de type Data Lake se situe au niveau de la gouvernance des données en général et plus précisément dans la difficulté à établir les rôles et les responsabilités par rapport à l’ensemble des données stockées, de trouver un juste milieu entre le fait de favoriser l’utilisation de la data sans silos par un maximum d’acteurs et la gestion de la sécurité.
Le Data Lake demande aussi un travail important de définition des différents environnements et des process permettant l’industrialisation des modèles statistiques élaborées en mode Lab. Enfin, d’un point de vue technique, le maintien des multiples outils et solutions potentielles et la gestion des versions nécessitent des ressources pointues et variées.
Cette difficulté potentielle à domestiquer son Data Lake a été décrite avec l’expression « From Data Lake to Data Swamp (du lac de données au marécage de données) » qui illustre la transformation progressive du Data Lake en un vaste espace de stockage non gouverné, non documenté, non sécurisé et finalement difficilement utilisable.
Data Lakehouse
Depuis quelques années, une réflexion a donc été menée pour concilier la souplesse et le coût réduit des Data Lake avec les capacités analytiques des Data Warehouse dans de nouvelles architectures de données, appelées Data Lakehouse ou encore Modern Data Platform et Modern Data Store.
- Tout d’abord, le Data Lakehouse va implémenter le support des propriétés ACID des transactions permettant de s’assurer de leur fiabilité. Il s’agit de s’assurer de la possibilité pour tous les intervenants de lire et d’écrire de manière simultanées les données quel que soit le type de données stockées, le type de stockage adopté, le format d’ingestion adopté et donc de maintenir la cohérence du système au cours du temps. Il s’agit plus précisément de travailler avec des données non structurées et issus de l’IOT comme avec des données structurées chargées en batch.
- Le Data Lakehouse va également s’ouvrir à tout type de clients en combinant outils de BI et de data visualisation traditionnels, langages Open Source (R, Python, Scala) et DataFrame API de façon à couvrir tous les usages de l’entreprise des plus basiques ou plus novateurs.
- Un des buts recherchés lors de la mise en place d’une architecture de données de type Data Lakehouse est aussi de réduire la redondance des données propre aux architectures Hadoop.
- Le Data Lakehouse va également implémenter l’ensemble des briques nécessaires à une gestion complète du cycle de vie des données, sans que l’on ait à se préoccuper de savoir où et comment ces dernières sont stockées. La gouvernance des données incluant les métadonnées, les contrôles d’accès et les audits est prévue au sein du Data Lakehouse
- Techniquement, le Data Lakehouse se caractérise généralement par l’usage de clusters séparés pour le stockage et le calcul et par des capacités à partager des données (Data Sharing) sans les dupliquer grâce à la couche de management des accès.
Acteurs
Parmi les principaux Data Lakehouse du marché, on peut citer tout d’abord ceux proposés par les principaux Cloud Service Providers (AWS, Azure et GCP) et construits autour de Azure Synapse Analytics, Amazon Redshift ou Google Bigquery et de la notion de « Serverless Compute ».
On trouve également parmi les acteurs de ces nouvelles architectures de données des pure players de la data comme Databricks qui propose Delta Lake ou encore Cloud Data Platform de Snowflake.
Snowflake est d’ailleurs un des acteurs qui a permis l’émergence de cette architecture alliant les capacités analytiques des Data Warehouse et les performances à coût contenu des Data Lake.
Enfin notons que Cloudera, acteur majeur du Big Data avec sa plateforme Hadoop, prend également le virage du Data Lakehouse.
Aujourd’hui, ces architectures présentent toutes les caractéristiques de gouvernance, de performance et de coût souhaitées par l’entreprise moderne.
Le Lakehouse permet donc d’explorer et d’exploiter pleinement les Big Data selon des méthodes éprouvées par la BI et de servir tous les usages de la data au sein d’une plateforme unique.
Le schéma ci-dessous synthétise cette évolution des plateformes de données :
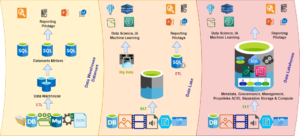
Dataware House & DataMart depuis 1995 Data Lake depuis 2005 Lake House depuis 2015