Problématique
Comment reconstituer un « trajet type » à partir des données de localisation GPS horodatées d’un ensemble de véhicules s’étant déplacé du point A au point B ?
Pour résoudre ce problème, l’algorithme ne doit reposer sur aucune donnée externe autre que :
- Les coordonnées des 2 points de départ (A) et d’arrivée (B)
- Les localisations GPS (X, Y) horodatées remontées par les véhicules ayant réalisés le trajet AàB
Méthodologie
Au vu des données disponibles, à savoir une projection spatio-temporelle de points GPS avec une concentration de points (X,Y) caractérisant l’itinéraire attendu, le recours aux deux méthodes suivantes est préconisé :
- L’algorithme DBSCAN pour enlever les points correspondant à des déviations ou à des données bruitées (erreur de mesure par exemple)
- La régression SPLINE, technique dite de lissage, pour construire l’itinéraire
Etape 1 – L’algorithme DBSCAN pour enlever les points atypiques
Avant de reconstruire la trajectoire à partir des données de localisation GPS, il est important d’isoler les points atypiques correspondant à des déviations du trajet habituel. Nous proposons d’utiliser l’algorithme Density-Based Spatial Clustering of Applications with Noise, communément appelé DBSCAN.
Il s’agit d’un algorithme de classification non supervisée basée sur la densité de points. Un groupe de points fortement concentrés sera perçu comme constituant une classe. Un point isolé, légèrement éloigné du groupe de points, sera considéré comme du bruit. Ce paradigme est particulièrement adapté à la détection de valeurs aberrantes.
Pour illustrer le fonctionnement de DBSCAN, prenons cet exemple classique où l’objectif est de segmenter le nuage de points en suivant les couleurs affichées. DBSCAN détermine les voisins de chaque point et évalue les trajectoires possibles en se déplaçant de voisin à voisin :

Sur cette figure, les voisinages sont représentés par des cercles. On peut se déplacer du point B au point C en passant de voisin à voisin. Par contre, on ne peut pas atteindre le point N à partir du point B. Le point N est alors considéré comme une valeur aberrante.
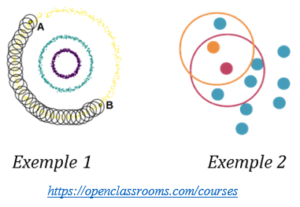
Cette manière de procéder permet de détecter des valeurs aberrantes sur un autre critère que la distance entre deux points. Par exemple sur l’exemple 1 ci-dessous, les points A et B sont les plus éloignés de la figure mais pourtant ils ont été réunis dans la même classe car atteignables l’un l’autre grâce à leur voisinage :
DBSCAN nécessite effectivement deux meta-paramètres :
- La distance nécessaire pour considérer deux points comme voisins.
- Le nombre de points nécessaires dans un voisinage pour considérer un point comme non aberrant.
L’exemple 2 illustre le choix du second paramètre : si le nombre de points est égal à quatre, le point orange n’est pas considéré comme une valeur aberrante car il appartient à un voisinage de 5 points (cercle rouge). En revanche, le point bleu juste au dessus est aberrant car le cercle orange ne contient que trois points.
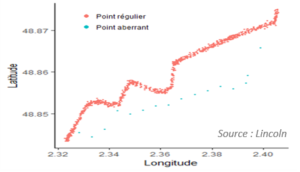
| Appliqué à notre problématique de détection de points atypiques dans les remontées GPS, l’algorithme DBSCAN isole parfaitement les données bruitées (déviation, erreur de mesure… |
Etape 2 – Régression Spline
Une fois les points atypiques isolés, nous utilisons la régression Spline qui est une technique dite de lissage. La régression Spline est une régression polynomiale par morceaux. L’idée est de séparer le nuage de points en plusieurs intervalles ; puis, sur chacun des intervalles, d’ajuster un modèle de régression polynomiale. En général, on utilise des polynômes de degré 3. On parle alors de Splines cubiques. La valeur des coefficients est pénalisée pour éviter d’avoir des coefficients trop élevés qui mèneraient à un sur-apprentissage.
Plus le nombre d’intervalles est élevé plus l’ajustement est précis. Chaque intervalle est délimité par des nœuds. Ci-dessous, une régression Spline à trois nœuds.

Cette méthodologie a été préconisée à un acteur du transport urbain pour répondre à la problématique de reconstruction des itinéraires de bus à partir des uniques données GPS remontées par les bus en circulation.Pour avoir un bon ajustement, il faut choisir un nombre de nœuds élevé. Ce nombre n’a pas besoin d’être choisi précisément pour donner de bons résultats mais doit être suffisamment élevé pour éviter le sous-ajustement. Les régressions Spline avec respectivement 20 et 100 nœuds donnent des résultats équivalents. Les résultats proposés sur notre cas d’étude ont été obtenus avec une vingtaine de nœuds.